
 https://coursera.org/share/f3e6bdfa539ff8c9d4b63f4a2b3d670a
https://coursera.org/share/f3e6bdfa539ff8c9d4b63f4a2b3d670a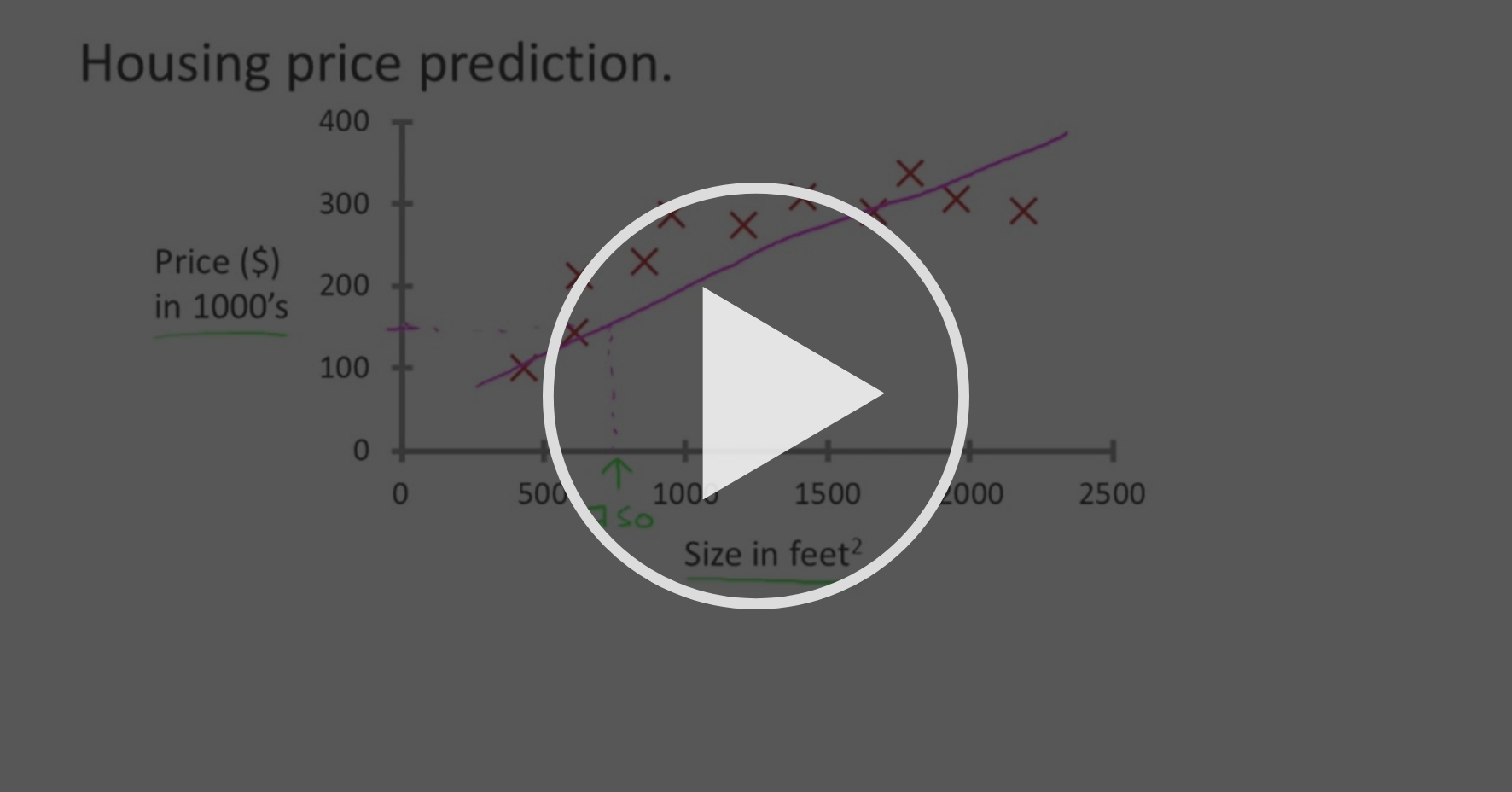
이번 강의에서는 아마 가장 일반적인 유형의 기계 학습 문제일 지도학습(Supervised Learning)에 대해 이야기할 것입니다 정식으로 지도학습에 대해 정의하는 건 나중에 하고, 우선은 이게 뭔지에 대한 설명이나 예를 먼저 살펴보고 공식적인 정의를 살펴보는 게 아무래도 가장 좋을 듯 합니다 가령 우리가 주택 가격을 예측하려 한다고 합시다. 얼마 전 어떤 학생이 오리건 주 포틀랜드 시의 데이터를 수집했는데 여러분이 데이터 집합을 이런 식으로 도식화했다고 합시다. 가로 축에는 서로 다른 주택의 크기가 제곱피트 단위로, 그리고 세로 축에는 서로 다른 주택의 가격이 천 달러 단위로 표시됐습니다 이런 데이터가 주어졌을 때 어떤 친구가 750 제곱피트짜리 집을 소유하고 있고, 그 집을 판매하려 하며, 얼마에 팔 수 있을지 알고 싶어 한다고 합시다. 이럴 때 학습 알고리즘이 어떻게 여러분을 도울 수 있을까요? 학습 알고리즘에서 한 가지 해볼 만한 것은 데이터를 통과하는 직선을 하나 그리는 겁니다 직선 하나를 데이터에 맞추는거죠(fit) 이를 통해 보면, 집을 15만 달러정도에 팔 수 있을 듯 하네요 하지만 이게 쓸 수 있는 유일한 학습 알고리즘은 아니고 더 좋은 게 있을 수도 있겠습니다 예를 들어, 직선을 데이터에 맞추는 대신 이차 함수, 즉 이차 함수을 맞추는 것이 낫다고 판단할 수도 있습니다 그렇게 했다고 하고 여기쯤에 예상을 해보면 그러면 아마도 20만 달러 가까이에 집을 팔 수도 있겠군요 나중에 이야기할 것들 중 하나가 바로 직선을 맞출지, 또는 이차 함수를 맞출지 등과 같은 판단을 어떻게 내려야 하는지입니다 어떤 것을 선택하든 친구의 팔 집이 더 좋아지거나 하지는 않죠. 하지만 이들은 각기 훌륭한 학습 알고리즘의 예시입니다. 자, 이것들은 지도학습 알고리즘의 예입니다. "지도학습"이라는 용어는 우리가 알고리즘에게 데이터 집합을 주는데, 각 데이터에 '정답'이 포함돼있는 겁니다 다시 말해 집에 대한 데이터 집합을 제공했는데, 각 집마다 정확한 가격도 알려준 겁니다 그 집이 매매된 실제 가격을 말이죠 이제 알고리즘의 역할은 그 '정답'을 더 많이 만들어내는 겁니다 친구가 판매하려 하는 이 집에 대한 것도 포함해서 말이죠 용어를 한 가지 더 정의하자면 이건 회귀 문제(regression problem)라고도 합니다 회귀 문제라고 함은 연속된 값을 가진 결과를 예측하려 한다는 겁니다 가격처럼요 가격은 가장 가까운 센트로 반올림하면 되겠죠 그러니까, 가격은 사실 불연속이죠 하지만 보통은 집값을 실수로, 스칼라 값으로, 즉 연속된 값을 가진 숫자로 생각하고, 회귀라는 용어는 우리가 이런 연속이라는 특징을 가진 값을 예측하려고 한다는 것을 뜻합니다 여기 다른 지도학습 예시를 보겠습니다 나와 몇몇 친구들이 실제로 전에 이 문제를 다뤘었습니다 의료기록을 보고 유방암이 악성인지 양성인지 예측하고 싶다고 합시다 만약 어떤 사람이 유방에 응어리, 즉 종양을 발견한 했을 때 악성 종양은 해롭고 위험한 경우이고 양성 종양은 무해한 경우입니다 당연히 사람들은 이것에 관심이 많겠죠 수집된 데이터 집합을 봅시다 데이터 집합에서 가로 축에는 종양의 크기를, 그리고 세로 축에는 1 또는 0, 즉 yes 또는 no를 도식할 겁니다 해당 예시의 종양이 악성이면 1, 악성이 아니면, 즉 양성이면 0입니다 그래서 데이터 집합은 다음과 같습니다 이만한 종양을 봤는데 양성이었고, 이런 크기도 있고 이런 크기도 있고, 등등 있습니다 슬프게도 몇몇 악성 종양도 봤는데요, 이런 크기에 하나, 이런 크기에 하나, 이런 크기도 하나, 등등이 있습니다 즉 이 예시에는 아래쪽에 표시된 양성 종양이 다섯 개가 있고 세로 축에서 1의 값을 가지는 악성 종양도 다섯 개가 있습니다 자 이제 어떤 친구가 비극적이게도 유방에 종양이 있는데, 그녀의 종양 크기가 한 이정도 값이라고 하면 기계학습으로 답하고 싶은 질문은 그 종양이 악성일 가능성이 얼마나 될지 예상해볼 수 있겠느냐 하는 것입니다 용어를 한 가지 더 소개하자면, 이 것은 분류 문제(classification problem)의 예시입니다 '분류'라는 용어는 이 경우 0 또는 1, 악성 또는 양성과 같이 불연속적인 결과값을 예측하려 한다는 겁니다 어떤 분류 문제는 결과가 두 개보다 많을 수도 있습니다 구체적인 예를 들면 유방암에 세 가지 종류가 있을 수도 있는 거죠 그러면 여러분은 0, 1, 2, 3 이라는 불연속적인 값을 예측하려 하는 거죠 가령 0은 양성 종양, 즉 암이 아닌 경우, 1은 첫 번째 종류의 암, 그러니까 세 종류의 암 중에서 어떤 하나겠죠 2는 두 번째 종류의 암, 그리고 3은 세 번째 종류의 암을 의미할 겁니다 하지만 이것 역시 분류 문제일 수 있는데 왜냐면 결과값들이 이산적이기 때문이죠. 암이 없다, 1번 종류의 암이다, 2번 종류의 암이다, 또는 3번 종류의 암이다, 이렇게요 분류 문제에서 이 데이터를 도식화할 수 있는 다른 방법이 있습니다. 제가 무슨 말을 하는건지 보여드릴께요. 제가 약간 다른 모양의 심볼들을 도식화에 사용해 보겠습니다 종양의 크기라는 속성을 가지고 제가 악성인지 양성인지를 예측한다고 하면 데이터를 이런식으로 그릴 수도 있습니다 무해한지 유해한지, 즉 예시가 음성인지 양성인지를 서로 다른 기호로 표시할 겁니다 가위표를 사용하는 대신 양성 종양은 이렇게 동그라미로 그리고 악성 종양은 계속 가위표로 그리겠습니다 뭘 하는 건지 이해되면 좋겠네요. 그냥 위쪽에 있는 데이터를 아래쪽에 있는 실수 선 위에 이렇게 배치하고 다른 기호를 사용하기 시작했습니다. 동그라미와 가위표가 각각 악성과 양성을 나타내도록 말이죠. 이 예시에선 단 하나의 특성(feature), 또는 속성(attribute)만 사용하죠 즉, 종양의 크기로 종양이 악성인지 양성인지 예측하고자 합니다 또 다른 기계 학습 문제에서는 한 개 이상의 특징, 한 개 이상의 속성이 주어지기도 합니다 이 예시를 봅시다. 종양의 크기만 아는 게 아니라 환자의 나이와 종양의 크기를 둘 다 안다고 해보죠 그런 경우 데이터 집합이 이렇게 보이겠죠 어떤 집단의 환자들이 이런 나이와 이런 종양 크기를 가지며 이렇게 보이고요, 또 다른 집단의 환자들은 좀 다르게 보입니다 가위표가 보여주듯이, 이 환자들의 종양은 악성이었던 겁니다 자 이제 어떤 친구가 비극적이게도 종양이 있는데, 그의 종양 크기와 나이가 이정도라고 합시다 그러면 이런 데이터 집합이 주어졌을 때 학습 알고리즘이 해볼 수 있는 건, 데이터에 직선을 하나 맞춰서 악성 종양을 양성 종양과 분리해보는 거죠 즉 학습 알고리즘이 이런 직선을 하나 그어서 두 종류의 종양을 분리해내는 겁니다 이러면 희망적으로, 그 친구의 종양에 대해서 여기, 이 쪽에 있죠. 희망적이게도, 학습 알고리즘은 그 친구의 종양이 이 양성인 쪽에 있기 때문에 악성보다는 양성일 가능성이 높다고 할 겁니다 이 예시에서는 특성이 두 개 있었죠, 정확히는 환자의 나이와 종양의 크기입니다 또 다른 기계 학습 문제에서는 더 많은 특성이 있는 경우도 잦습니다 이 문제를 다룬 내 동료들은 사실 다른 특성들도 썼는데요 응어리의 두께, 그러니까 유방 종양의 두께, 종양 세포의 크기의 일관성, 종양 세포의 모양의 일관성 등등 입니다. 다른 특성도 더 있고요. 사실 이 강좌에서 다룰 학습 알고리즘에서 가장 흥미로운 것들 중 하나는 특성을 겨우 두 개나 세 개, 아니면 다섯 개 정도 다루는 게 아닌 무한한 수의 특성을 다루는 학습 알고리즘입니다 이 슬라이드에선 제가 총 다섯 개의 서로 다른 특성을 나열했습니다 축에 두 개, 그리고 이 쪽에 세 개 더요 하지만 어떤 학습 문제에선 고작 세 개, 다섯 개, 이정도 수의 특성이 아니라 무한히 많은 특성을, 무한히 많은 속성을 다룰 필요가 있습니다 그래야 학습 알고리즘이 수많은 속성, 또는 특성이나 신호(cue)를 통해 예측을 할 수 있는 거죠 그러면, 무한한 개수의 특성은 어떻게 다뤄야 할까요? 이렇게 무한대의 특성을 컴퓨터의 메모리에 저장하게 되면 컴퓨터의 메모리 용량을 다 써버리게 될텐데 말이죠. 우리가 나중에 논의할 서포트 벡터 머신(Support Vector Machine)이라는 알고리즘에서 어떤 깔끔한 수학적 방법을 사용하면 컴퓨터가 무한한 개수의 특성을 다룰 수 있게 됩니다 제가 여기 특성 두 개랑 여기 특성 세 개를 적은게 아니라 무한히 긴 특성의 목록을 적었다고 상상해보세요 특성을 그냥 계속 적어나가서 무한히 긴 특성의 목록이 된 겁니다 우린 이런 것을 다룰 수 있는 알고리즘을 생각해낼 겁니다 자, 정리해보자면, 우린 이번 강의에서 우린 지도 학습에 대해 이야기했고 지도 학습에서의 아이디어는 데이터 집합 안에 있는 모든 예시에 대해 알고리즘이 예측해냈으면 하는 정답이 우리에게 주어지는 겁니다 가령 집값이나 종양이 악성인지 양성인지 같은거요 또 회귀 문제에 대해서도 이야기했죠 회귀라 함은, 우리의 연속적인 출력값을 예측하려 한다는 겁니다 그리고 분류 문제에 대해서도 이야기했는데요, 이산적인 출력값을 예측하는 게 목표입니다 마무리하는 의미에서 질문을 하나 하겠습니다 여러분이 회사를 경영하고 있고 두 개의 문제를 해결하기 위해 학습 알고리즘을 개발한다고 합시다 첫 번째 문제에서 당신은 동일한 물건으로 이루어진 대량의 재고가 있습니다 그러니까, 팔아야 하는 똑같은 물건이 수천 개 있고 3개월 안에 그 중에서 몇 개나 팔릴지 예측하고 싶다고 상상해보세요 두 번째 문제에선 당신은 많은 수의 유저를 보유하고 있고 고객의 계정 각각을 조사하는 소프트웨어를 작성하고 싶다고 합시다 각 계정에 대해, 그 계정이 해킹 또는 손상됐는지 판단하는 겁니다 자, 그러면 각 문제를 분류 문제로 봐야 할까요, 아니면 회귀 문제로 봐야 할까요? 비디오가 일시정지되면 마우스를 사용해서 네 선지 중에 정답이라고 생각하는 것을 고르기 바랍니다
자, 다들 맞추셨나요? 이게 정답이죠 첫 번째 문제는 저라면 회귀 문제로 다룰 겁니다. 왜냐하면 물건이 수천 개나 있어서 그냥 이걸 실수(real number)로 볼 것 같거든요 연속적인 값으로요 즉, 제가 팔려는 물건의 수를 연속인 값으로요 두 번째 문제는 저라면 분류 문제로 다룰겁니다 왜냐하면 예측하고자 하는 값을 0으로 설정하여 계정이 해킹 당하지 않았음을, 그리고 1로 하여 계정이 해킹 당했음을 나타낼 수 있기 때문입니다 결국 0이 양성, 1이 악성이었던 유방 종양의 경우와 똑같습니다 그러므로 저는 해킹 여부에 따라 0이나 1의 값을 설정할 것이고, 알고리즘이 이 두 이산적인 값을 예측하게 할 겁니다 이산적인 값의 수가 적기 때문에 분류 문제로 다루는 것입니다 그러면, 지도 학습은 여기까지입니다 다음 비디오에서, 학습 알고리즘의 또 다른 중요한 분야인 비지도 학습에 대해 이야기하겠습니다

Uploaded by Notion2Tistory v1.1.0