
 https://coursera.org/share/8c1524abfa46e7d33f793acac0e1b2c2
https://coursera.org/share/8c1524abfa46e7d33f793acac0e1b2c2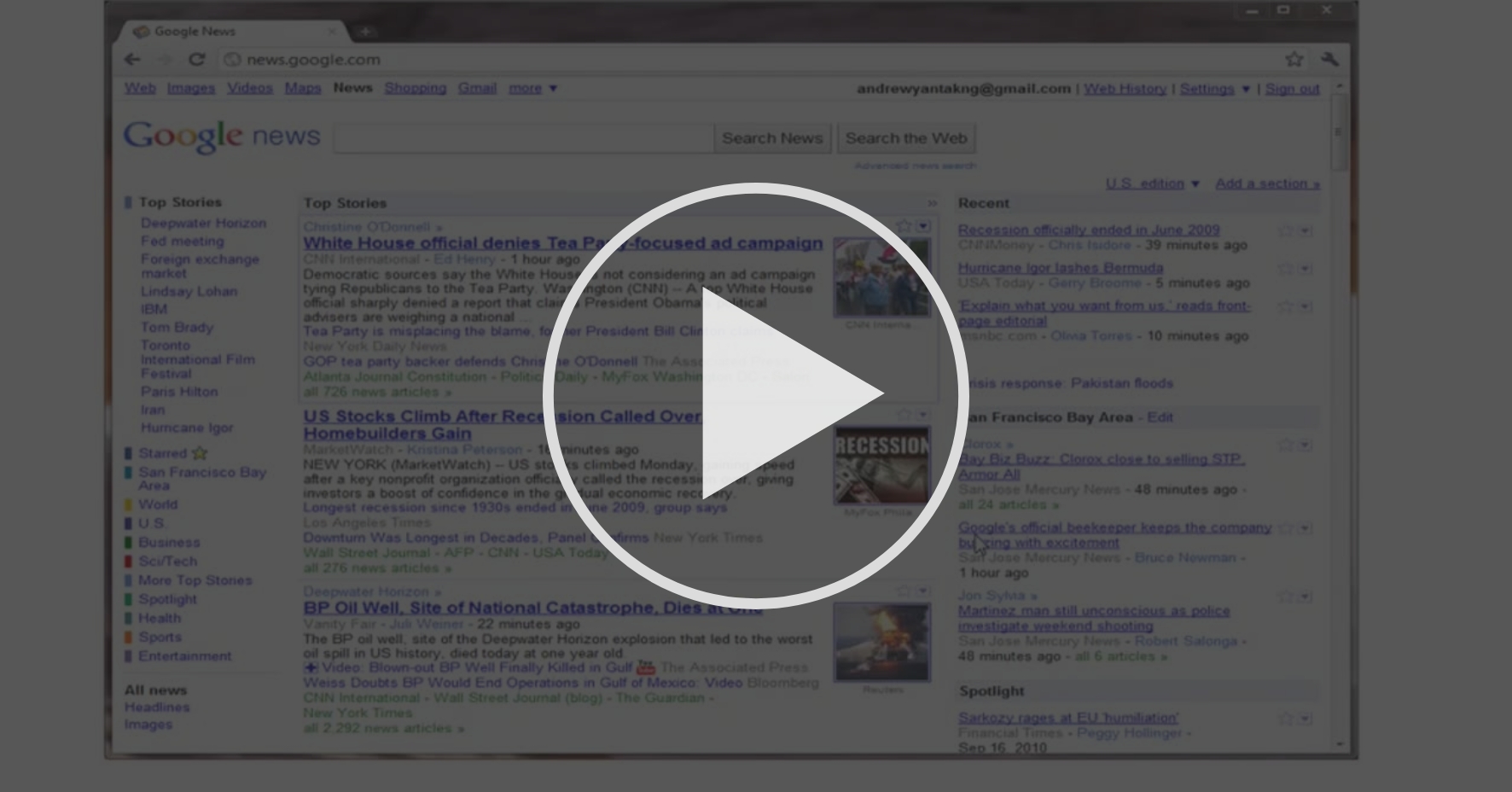
이 비디오에서는, 우리는 비지도 학습(unsupervised learning)이라고 불리는 기계 학습 문제의 두번째 주요 유형에 대해 이야기해봅시다 이전 비디오에선, 지도 학습에 대해 이야기 했습니다 그때로 뒤돌아가서, 화면에 보이는 것처럼 양성 또는 음성이라고 레이블(label)된 데이터를 불러와 봅시다 이 데이터는 양성 종양인지 또는 악성 종양인지를 나타냅니다 그래서, 각 지도 학습의 예시는 우리는 명시적으로 어떤 게 양성인지 악성인지 소위 말하는 정답이 주어져 있습니다 비지도 학습에서는 데이터가 이렇게 보이는 것과 다르게 주어집니다 이와 같이 데이터가 주어집니다 어떤 레이블도 갖고 있지 않거나, 모두 같은 레이블을 갖고 있거나, 또는 아예 레이블이 없습니다 그래서 우리에게 주어진 데이터 집합에 우리는 이것으로 무엇을 할지, 또 각 데이터가 무엇인지 알 수 없습니다 대신에 단지 우리에게 "여기 데이터가 있는데, 여기서 어떤 구조를 찾을 수 있습니까?"라고 물을 뿐입니다 주어진 이 데이터 집합에서 비지도 학습 알고리즘은 두 가지 다른 클러스터(cluster)로 되어 있다고 판단할 수도 있습니다 즉 여기에 클러스터 하나, 여기에 또 다른 클러스터가 있습니다 비지도 학습 알고리즘은 이 데이터를 두가지 서로 다른 클러스터로 구분 지을 수도 있습니다 그래서 이것은 클러스터링 알고리즘이라고 불립니다 그리고 이 알고리즘은 많은 곳에서 사용되고 있습니다 한 가지 예로 이 클러스터링 알고리즘이 사용되고 있는 곳은 구글 뉴스입니다 이걸 한 번도 본 적이 없으면, news.google.com URL로 가서 확인할 수 있습니다 구글 뉴스가 하는 일은 웹에서 매일 수만, 수천 가지의 새로운 기사들을 조사하는 것입니다 그리고 그 기사들을 연관성이 있는 것끼리 묶습니다 예를 들어봅시다. 여기를 보면, 이 URL들은 BP Oil Well 토픽에 대한 서로 다른 기사들을 링크합니다 자, 이 URL 중 하나를 클릭해봅시다. 제가 하나의 URL을 클릭하면, 이와 같은 웹 페이지에 들어갈 수 있습니다 여기는 BP Oil에 대한 월스트리트 저널의 기사입니다 "BP Kills Macondo", 이게 기름유출의 이름이죠 이 그룹의 다른 기사의 URL을 클릭해보면, 아마 또 다른 이야기를 확인할 수 있으실 겁니다 여기는 BP 기름 유출의 CNN의 기사군요 그리고 또 다른 세번째 링크를 클릭해보면 또 다른 기사를 확인할 수 있습니다 여기는 BP 기름 유출에 대한 UK 가디언의 기사군요 그래서 구글 뉴스의 우위는 말 그대로 수만 개의 기사들과 자동적으로 그 기사들을 묶어준다는 겁니다. 그래서 기사들이, 같은 토픽의 모든 기사들은 같이 묶여 표시되는 겁니다 클러스터링 알고리즘과 비지도 학습 알고리즘은 다른 많은 문제에서도 사용됩니다 유전학적 자료 이해에 대한 것입니다. 이것은 DNA 미세배열의 한 예시입니다. 어떤 거냐면, 서로 다른 사람들의 그룹이 있고, 각 사람에 대해 특정 유전자를 가지고 있는지 또는 그렇지 않은지를 측정하는 겁니다 엄밀히 말하면, 특정 유전자가 얼마나 발현되었는지를 측정합니다 그러니까 이 색깔들, 빨강, 초록, 회색 등등이 어떤 개인이 특정 유전자를 얼마나 가졌느냐를 보여줍니다 이러면 이제 우리는 클러스터링 알고리즘을 돌려서 사람들을 서로 다른 분류 또는 타입으로 묶을 수 있습니다 자, 이게 비지도 학습입니다. 왜냐하면 우리는 알고리즘에게 미리 이 사람들은 1번 타입, 저 사람들은 2번 타입, 저 사람들은 3번 타입 이렇게 알려주지 않고, 대신에 "여기 데이터가 엄청 있는데 우선적으로 data가 어떤 것인지 모르고 누구의 data이고 어떤 유형인지도 모릅니다. 사람들에 어떤 타입이 있는지도 사실 모르는데, 이 데이터에서 알아서 구조를 찾아내줄 수 있겠니? 자동으로 각 사람을 뭔진 모르지만 어떤 타입으로 클러스터링해줄 수 있겠니?"라고 하는거죠 알고리즘에게 데이터 집합의 예시에 대해 정답을 주고 있지 않기 때문에 이건 비지도 학습입니다 비지도 학습, 또는 클러스터링은 다른 곳에서도 많이 응용됩니다 대규모 컴퓨터 클러스터를 구성할 때 사용됩니다. 내 몇몇 동료들은 데이터 센터, 그러니까 거대한 컴퓨터 클러스터를 보고 어떤 기기들끼리 주로 같이 일하는지 알아내려고 했습니다 만약 그 기기들을 같이 둔다면 data centers를 더 효율적이게 만들 수 있습니다. 두 번째 예시입니다 소셜 네트워크 분석 즉, 여러분이 어떤 친구에게 이메일을 가장 많이 보내는지 또는 페이스북 친구나 구글 플러스 써글에 대한 정보가 주어질 때 자동적으로 어떤 게 적절한 친구 그룹인지, 그리고 서로서로 다 아는 사람들의 그룹인지를 찾을 수 있을까 하는 것입니다 이번은 시장 세분화입니다. 많은 회사는 고객 정보의 거대한 데이터베이스를 가지고 있습니다. 이 고객에 대한 데이터 집합을 보고 자동적으로 세분화된 시장을 찾아내고, 자동적으로 고객들을 세분화된 시장 안으로 묶어 넣어서 자동적으로 그리고 더욱 효율적으로 세분 시장에서 판매와 영업을 동시에 할 수 있습니다 이 또한 비지도 학습입니다. 왜냐하면 우리가 고객 정보는 가지고 있지만, 우리가 미리 세분화된 시장이 뭔지 알지 못하고, 데이터 집합에 있는 고객에 대해 누가 1번 세분 시장에 있는지, 누가 2번 세분시장에 있는지 등등을 미리 알고있지 않기 때문입니다 다만 우리는 알고리즘이 스스로, 오직 데이터로부터 알아내게 하는 겁니다 마지막으로, 비지도 학습은 놀랍게도 천문학 데이터 분석에 사용됩니다 또한 이런 클러스터링 알고리즘은 은하계의 생성에 관해 굉장히 흥미롭고 유용한 이론을 가져다줍니다 이 모든 것은 비지도 학습의 한 분류일 뿐인 클러스터링의 예시입니다 이제 다른 예제에 대해 이야기 해보겠습니다. 칵테일 파티 문제에 대해 이햐기해드리죠 여러분들은 전에 칵테일 파티에 가본 적이 있나요? 파티 룸 가득 사람들이 앉아서 모두 동시에 이야기를 하는 걸 상상할 수 있을 겁니다 이러면 중첩되는 목소리가 많죠. 왜냐하면 모든 사람이 동시에 이야기를 하고 있고, 앞에 있는 사람이 하는 말도 듣기 어렵습니다 자, 그러면 어떤 칵테일 파티에서 두 사람이 동시에 이야기를 하고 있을 수 있죠 꽤나 작은 칵테일 파티인데, 우리가 방에 마이크를 두 개 둘 겁니다 이렇게, 마이크가 있어요. 그리고 이 마이크들이 말하는 사람으로부터 서로 다른 거리에 있기 때문에 각 마이크는 말하는 두 사람의 목소리의 서로 다른 조합을 녹음하게 됩니다 1번 화자는 1번 마이크에서 좀 더 소리가 클 수도 있고 2번 화자는 2번 마이크에서 좀 더 소리가 클 수 있죠. 왜냐하면 두 마이크가 두 화자에 대해 서로 다른 위치에 있기 때문이죠 각 마이크는 두 목소리가 조합되어 중첩된 것을 녹음합니다 연구자에 의해 실제로 녹음된 두 화자의 목소리입니다 재생해볼게요 첫 번째 마이크의 소리입니다 [두 사람이 각각 스페인어와 영어로 1부터 10까지 세는 음성] [두 사람이 각각 스페인어와 영어로 1부터 10까지 세는 음성] [두 사람이 각각 스페인어와 영어로 1부터 10까지 세는 음성] 좋아요. 엄청나게 흥미를 끄는 칵테일 파티는 아닐 수도 있겠네요 두 사람이 두 개의 언어로 1부터 10까지 세고 있습니다 여러분이 방금 들은 건 첫 번째 마이크의 녹음이고요 이게 두 번째 녹음입니다 [두 사람이 각각 스페인어와 영어로 1부터 10까지 세는 음성] [두 사람이 각각 스페인어와 영어로 1부터 10까지 세는 음성] [두 사람이 각각 스페인어와 영어로 1부터 10까지 세는 음성] 그래서, 이 두 마이크의 녹음을 가져다가 칵테일 파티 알고리즘이라 불리는 비지도 학습 알고리즘에게 주고 "이 데이터에서 구조를 찾아내줘" 라고 말하는 겁니다 알고리즘은 이 두 음성녹음을 들어보고 이것이 두 음성녹음이 더해져서, 또는 합쳐져서 우리가 가진 녹음이 되는 것 같다고 할 겁니다 나아가 칵테일 파티 알고리즘은 더해져서, 또는 합쳐져서 우리의 녹음을 이루는 두 개의 음성 소스를 분리해 낼 겁니다 이게 칵테일 파티 알고리즘의 첫 번째 출력입니다 (영어로) 하나, 둘, 셋, 넷, (영어로) 다섯, 여섯, 일곱, 여덟, 아홉, 열 하나의 녹음에서 영어를 분리해냈죠 이게 두 번째 출력입니다 (스페인어로) 하나, 둘, 셋, 넷, 다섯, 여섯, 일곱, 여덟, 아홉, 열 나쁘지 않죠? 예시를 하나 더 드리자면 이건 다른 비슷한 상황을 녹음한 겁니다. 이게 첫 번째 마이크예요 (배경음악과 함께 영어로) 하나, 둘, 셋, 넷, (배경음악과 함께 영어로) 다섯, 여섯, 일곱, 여덟, 아홉, 열 자, 이제 이 불쌍한 남자는 칵테일 파티에서 나온 후 집으로 가고, 그는 지금 방에 앉아있습니다. 이건 2번 마이크에 녹음된 내용입니다. (배경음악과 함께 영어로) 하나, 둘, 셋, 넷, 다섯, 여섯, 일곱, 여덟, 아홉, 열 아까와 같은 알고리즘에게 이 마이크 녹음을 주면 이번 역시 똑같이 오디오 소스가 두 개 있는 것 같고, 나아가 이게 첫 번째 오디오 소스라고 할 겁니다 (영어로) 하나, 둘, 셋, 넷, 다섯, (영어로) 여섯, 일곱, 여덟, 아홉, 열 뭐, 완벽하진 않앗죠 목소리를 잡아내긴 했지만 음악도 조금 잡혔어요 이게 알고리즘의 두 번째 출력입니다
나쁘지 않아요. 두 번째 출력에선 목소리를 완전히 없애는 데 성공했죠 1부터 10까지 세는 걸 지우고 음악 소리를 깨끗하게 했어요 자, 이런 비지도 학습 알고리즘을 보고 여러분은 이걸 구현하는 게 얼마나 복잡한지 물을 수 있어요 이런 응용 프로그램을 만드려면, 이런 오디오 처리를 해내려면 엄청나게 많은 코드를 쓰거나, 오디오를 처리해주는 C++, Java 라이브러리를 가져오거나 해야할듯 하죠 이렇게 오디오를 분리해내거나 하려면 상당히 복잡한 프로그램일 거라 생각되겠죠 알고보니 여러분이 방금 들은 일을 하는 알고리즘은 한 줄의 코드로 가능합니다. 여기 이겁니다 이 한 줄의 코드를 만들기 위해 연구자들에게 긴 시간이 걸리긴 했죠 그래서 이 문제가 쉽다고 말하는 건 아니지만 여러분이 적당한 프로그래밍 환경을 사용한다면 많은 학습 알고리즘들을 간단히 프로그래밍할 수 있습니다 이것이 우리가 수업에서 Octave 프로그래밍 환경을 사용할 이유이기도 합니다 Octave는 무료로 공개된(open source) 소프트웨어입니다 Octave나 Matlab같은 도구를 사용하면 많은 학습 알고리즘을 단지 몇 줄의 코드로 구현할 수 있습니다 이 수업에서 나중에 Octave의 사용법을 조금 가르칠 겁니다 그러면 여러분은 몇몇 알고리즘을 Octave로, 또는 Matlab이 있다면 그걸로 구현하게 될 겁니다 실리콘 밸리에서는 많은 기계 학습 알고리즘에 대해 우선 Octave로 소프트웨어의 프로토타입을 만들어 봅니다. 왜냐하면 Octave가 이런 학습 알고리즘을 매우 빨리 구현하게 해주기 때문입니다 여기서 각각의 함수들은, 예를 들어 SVD함수는 특이값 분해(singular value decomposition)의 약자인데 이는 선형 대수학의 과정 중 하나로 Octave에 그냥 내장되어 있습니다 이걸 C++이나 Java로 하려 했다면 복잡한 C++, Java 라이브러리를 동반한 많은 양의 코드였을 겁니다 그러니까, C++, Java, 또는 Python으로도 이런 걸 구현할 수 있어요 하지만 이런 언어들로는 단지 더 복잡할 뿐입니다 프랑스에서 한 10년 간 기계 학습을 가르치면서 내가 보아온 것은, Octave를 프로그래밍 환경으로 사용했을 때 훨씬 빠르게 배운다는 겁니다 Octave를 학습 도구로, 그리고 프로토타입 제작 도구로 사용하면 더 빨리 알고리즘을 배우고 프로토타입으로 만들 수 있을 겁니다 사실, 실리콘밸리에 있는 대형 회사 사람들은 많이들 Octave같은 언어를 사용하여 학습 알고리즘의 프로토타입을 만들어보고, 그게 동작한 다음에야 그걸 C++이나 Java로 옮깁니다 이런 방식으로 일을 하면 많은 경우 알고리즘을 C++로 작성하는 것보다 빠르게 구현이 가능할것 입니다. 사실 제가 강의자로서 항상 "이건 그냥 절 믿어보세요"라고 말할 수는 없어요 하지만 Octave같은 프로그래밍 환경을 한 번도 사용해보지 않은 분들에게 이건 그냥 절 믿어주셨으면 한다고 말하고 싶어요. 여러분의 시간, 여러분의 개발 시간은 가장 귀중한 자원중 하나이고, 다른 사람들이 이렇게 하는 걸 봐온 결과 기계 학습 연구자나 기계 학습 개발자로서 당신이 이런 것들을 배우고 Octave같은 언어로 프로토타입을 만든다면 훨씬 더 효율적일 수 있다고 생각합니다 마지막으로, 이번 비디오를 마무리하는 의미에서 간단한 복습 문제가 하나 있습니다 우린 비지도 학습에 대해 이야기했죠 이 학습 환경에선 알고리즘에게 데이터를 다량 주고 그 안에서 알아서 구조를 찾아내도록 했습니다 다음 네 개의 예시 중 어떤 것들이 지도 학습 문제이기보단 비지도 학습 문제일까요? 왼쪽에 있는 네 개의 체크박스에 대해 비지도 학습 알고리즘이 적절하다고 생각하는 것을 체크하고 오른쪽 아래 버튼을 클릭 하세요 비디오가 멈추면 슬라이드에 나오는 문제에 답해보세요 스팸 메일함 문제를 기억했나요? 스팸인지 아닌지 레이블된 데이터를 가지고 있으면 지도 학습 문제로 다룹니다 뉴스 기사 예시, 정확히 구글 뉴스의 예시는 이번 비디오에 나왔습니다 클러스터링 알고리즘으로 뉴스 기사들을 묶는 걸 봤죠 그러므로 비지도 학습입니다 시장 세분화 예시는 아까 전에 언급했는데요, 이건 비지도 학습 문제로 풀 수 있습니다. 왜냐하면 알고리즘이 데이터를 보고 세분화된 시장을 자동으로 발견하기 때문입니다 마지막 예시인 당뇨는, 사실 직전 비디오의 유방암 예시와 똑같습니다 단지 좋은/나쁜 암 종양, 또는 양성/악성인지 대신에 당뇨인지 아닌지를 볼 뿐입니다 그러므로 이건 유방암 데이터와 똑같이 지도 학습 문제로 풀게 됩니다 자, 여기까지가 비지도 학습이고요 다음 비디오에서는 더 구체적인 학습 알고리즘으로 파고들면서 이런 알고리즘이 어떻게 동작하고 어떻게 구현해야 하는지 이야기할 겁니다

Uploaded by Notion2Tistory v1.1.0